The third edition of the Graz-Vienna Speech Workshop is hosted by the Speech and Hearing Science Labs (SHS-Labs) of the Medical University of Vienna.
The workshop aims at bringing together speech scientists and technologists with a dedicated focus on health sciences and medical applications, particularly in the field of speech-language-hearing pathologies. This workshop will feature oral plenary talks and practical sessions to facilitate discussions on work in progress, showcase new methods, and explore innovative interdisciplinary approaches. Topics of interest include, but are not limited to, speech communication sciences, artificial intelligence, machine learning, automated speech recognition, assistive technologies for rehabiliation, phonetics, linguistics, psychology, medical imaging, and digital health.
Thank you!


Program
Wednesday, 23. April 2025
Room: Hörsaal 5
- 12:00 - 13:00 hrs
Registration
- 13:00 - 13:10 hrs
Welcome by the organizers
Room: Hörsaal 5
Chair: Veronika Mattes (Department of Linguistics, University of Graz)
- 13:10 - 13:30 hrs
On the Vowel Development of Bilingual Kindergarten Children in their L2 German
Carolin Schmid (Department of Pediatrics and Adolescent Medicine, Medical University of Vienna)
- 13:30 - 13:50 hrs
Expressive Vocabulary Development in Children with Permanent Hearing Loss: Early Nonverbal Predictors
Anna-Lena Feichter (Department of Linguistics, University of Graz)
- 13:50 - 14:10 hrs
Phonetic Analysis of Dysarthric Child Speech
Martina Galović (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 14:10 - 14:30 hrs
Towards Developing an Assistive Communication Tool for Dysarthric Children
Barbara Schuppler (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 14:30 - 14:50 hrs
Multi-Style Child TTS: An Expressive Text-to-Speech System for Children
Shaima Alwaisi (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 14:50 - 15:10 hrs
Wrap up & discussion
Room: Foyer, Level 8
- 14:50 - 15:10 hrs
Coffee break
Room: Hörsaal 5
Chair: Barbara Schuppler (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 15:40 - 16:00 hrs
An Acoustic and Articulatory Study of Voice Quality in Coarticulated Hanoi Vietnamese Tones
Yaqian Huang (Acoustics Research Institute, Austrian Academy of Science)
- 16:00 - 16:20 hrs
Does Spatial Auditory Attention Change After Having a Face-To-Face Conversation in a Noisy Environment?
Ľuboš Hládek (Acoustics Research Institute, Austrian Academy of Science)
- 16:20 - 16:40 hrs
(When) Does it Harm to Be Incomplete? Encoding ASR Mistranscriptions of Syntactically Disfluent Structures
Saskia Wepner (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 16:40 - 17:00 hrs
ASR of Non-lexical and Disfluent Events -an Investigation Across Tasks
Yan Meng (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 17:00 - 17:20 hrs
Speech Enhancement of Conversational Speech in Cocktail Party Noise
Emil Berger (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 17:20 - 17:40 hrs
Building a Robust HMI Command Inventory for Various Noisy Environments
Sara Marguerite Pearsell (Institute of Mechanical and Electrical Engineering, University of Southern Denmark)
- 17:40 - 18:00 hrs
Wrap up & Discussion
Thursday, 24. April 2025
Room: Hörsaal 5
Chair: Peter Mihajlik (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 09:00 - 09:20 hrs
Comparison of Self-Training Strategies for ASR
Yue Luo (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 09:20 - 09:40 hrs
Improving Khalkha Mongolian ASR via Transliteration-Based Transfer Learning
Dalai Mengke (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 09:40 - 10:00 hrs
Speech Event Extraction: An ASR+NLP Challenge
Máté Gedeon (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 10:00 - 10:20 hrs
Towards Creating a Carinthian Slovenian Spoken Language Resource
Andrej Žgank (Faculty of Electrical Engineering and Computer Science, University of Maribor)
- 10:20 - 10:40 hrs
Wrap up & Discussion
- 10:40 hrs
Group photo
Room: Foyer, Level 8
- 10:50 - 11:10 hrs
Coffee break
Room: Kursraum 21
- 11:10 - 11:55 hrs
How to Use SLICER for Stimuli Extraction from Large Speech Corpora
Lucas Eckert (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 12:00 - 12:45 hrs
Annotating Creak in Healthy and Pathological Voices
Anna Viehhauser (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
Room: Mensa/Personalspeiseraum, Level 5
- 12:45 - 14:00 hrs
Lunch break
Room: Kursraum 21
- 14:00 - 14:45 hrs
SpeechScape: An Easy-to-Use Tool for Clustering Speech Data Based on Self-Supervised Representations
Julian Linke (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 14:45 - 15:35 hrs
Speech Pauses in Alzheimer Disease: Exploring Challenges in Training Automatic Speech Recognition Systems
Sandra Lafenthaler (Department of Neurology, Neurointensive Care, and Neurorehabilitation, Paracelsus Medical University Salzburg)
- 15:40 - 16:25 hrs
From Medical Data to Models: Own Experiences and Challenges
Mario Fleischer (Department of Audiology and Phoniatrics, Charité – Universitätsmedizin Berlin)
Room: all rooms (Hörsaal 5, Kursräume 21-23)
- 16:30 - 17:30 hrs
Discussion and exchange in small self-organized groups
Room: Kursraum 22
- 11:10 - 12:45 hrs
Evidencing Physiological and Acoustic Outcomes of Clinical Voice Interventions Using Voice Maps
Sten Ternström (Department of Speech, Music and Hearing, KTH Royal Institute of Technology, Stockholm)
Room: Mensa/Personalspeiseraum, Level 5
- 12:45 - 14:00 hrs
Lunch break
Room: Kursraum 22
- 14:00 - 14:45 hrs
Optopalatography for Phonetic Research
Jihyeon Yun (Institute of Acoustics and Speech Communication, Dresden University of Technology)
- 14:50 - 15:35 hrs
Using Ultrasound Tongue Imaging for Phonetic Research
Nathalie Elsässer (Acoustics Research Institute, Austrian Academy of Sciences)
- 15:40 - 16:25 hrs
Analysis of Uni- and Multi-Dimensional Contours with GAMs and Functional PCA: an Application to Ultrasound Tongue Imaging
Michele Gubian (Institute for Phonetics and Speech Processing, LMU Munich)
Room: all rooms (Hörsaal 5, Kursräume 21-23)
- 16:30 - 17:30 hrs
Discussion and exchange in small self-organized groups
Friday, 25. April 2025
Room: Hörsaal 5
Chair: Philipp Aichinger (Department of Otorhinolaryngology, Medical University of Vienna)
- 09:00 - 09:20 hrs
Project Kick-Off: Voice Conversion for Pathological Speech
Martin Hagmüller (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
Philipp Aichinger (Department of Otorhinolaryngology, Medical University of Vienna)
- 09:20 - 09:40 hrs
Voice Conversion in Pathological Speech: Applications and Challenges
Benedikt Mayrhofer (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 09:40 - 10:00 hrs
Realtime Personalized Deep Learning Voice Morphing for Electrolaryngeal Speech in Polish Language
Pawel Cyrta (Uhura Bionics Ltd., Warsaw)
- 10:00 - 10:20 hrs
A Medical Application of ASR and LLM
Imre Gergely Jánoki (Department of Telecommunications and Artificial Intelligence, Budapest University of Technology and Economics)
- 10:20 - 10:40 hrs
The Mere-Measurement Effect in Patient-Reported Outcomes: A Randomized Controlled Trial with Speech Pathology Patients
Preston Long (Centre for Medical Data Science, Medical University of Vienna)
Room: Foyer, Level 8
- 10:40 - 11:00 hrs
Coffee break
Room: Kursraum 21
- 11:00 - 11:45 hrs
Speech-Based Cardiorespiratory Health Monitoring with VOICE-BIOME: a scalable voice biomarker platform
Prashanth Pombala (ZANA Technologies GmbH, Karlsruhe)
Room: Kursraum 22
- 11:00 - 11:45 hrs
Deep Learning ASR for a Patient with Permanent Tracheostomy
David Nadrchal (Institute of Computational Perception, Johannes Kepler University Linz)
Room: Hörsaal 5
Chair: Gernot Kubin (Signal Processing and Speech Communication Laboratory, Graz University of Technology)
- 11:50 - 12:10 hrs
Physically-Based Machine Learning for Vocal Fold Video Data Interpretation
Carlo Drioli (Dept. of Mathematics, Computer Science, and Physics DMIF, University of Udine)
- 12:10 - 12:30 hrs
Sampling Rate Bias of Vocal Jitter and Shimmer
Jean Schoentgen (Laboratories of Image, Signal Processing and Acoustics, Université Libre de Bruxelles)
- 12:30 - 12:50 hrs
Resonance Frequencies in Non-Rigid Compressed Waveguides
Annemie Van Hirtum (Laboratoire des Écoulements Géophysiques et Industriels LEGI, University of Grenoble Alpes)
- 12:50 - 13:10 hrs
Physical Model of Phonation with Reduced and Measurable Parameters
Xavier Pelorson (Laboratoire des Écoulements Géophysiques et Industriels LEGI, University of Grenoble Alpes)
- 13:10 - 13:30 hrs
Wrap up & Discussion
Room: Mensa/Personalspeiseraum, Level 5
- 13:30 - 14:30 hrs
Farewell lunch
Registration
Contact
Philipp Aichinger
+43 (0)1 40400-33790
philipp.aichinger@meduniwien.ac.at
Department of Otorhinolaryngology
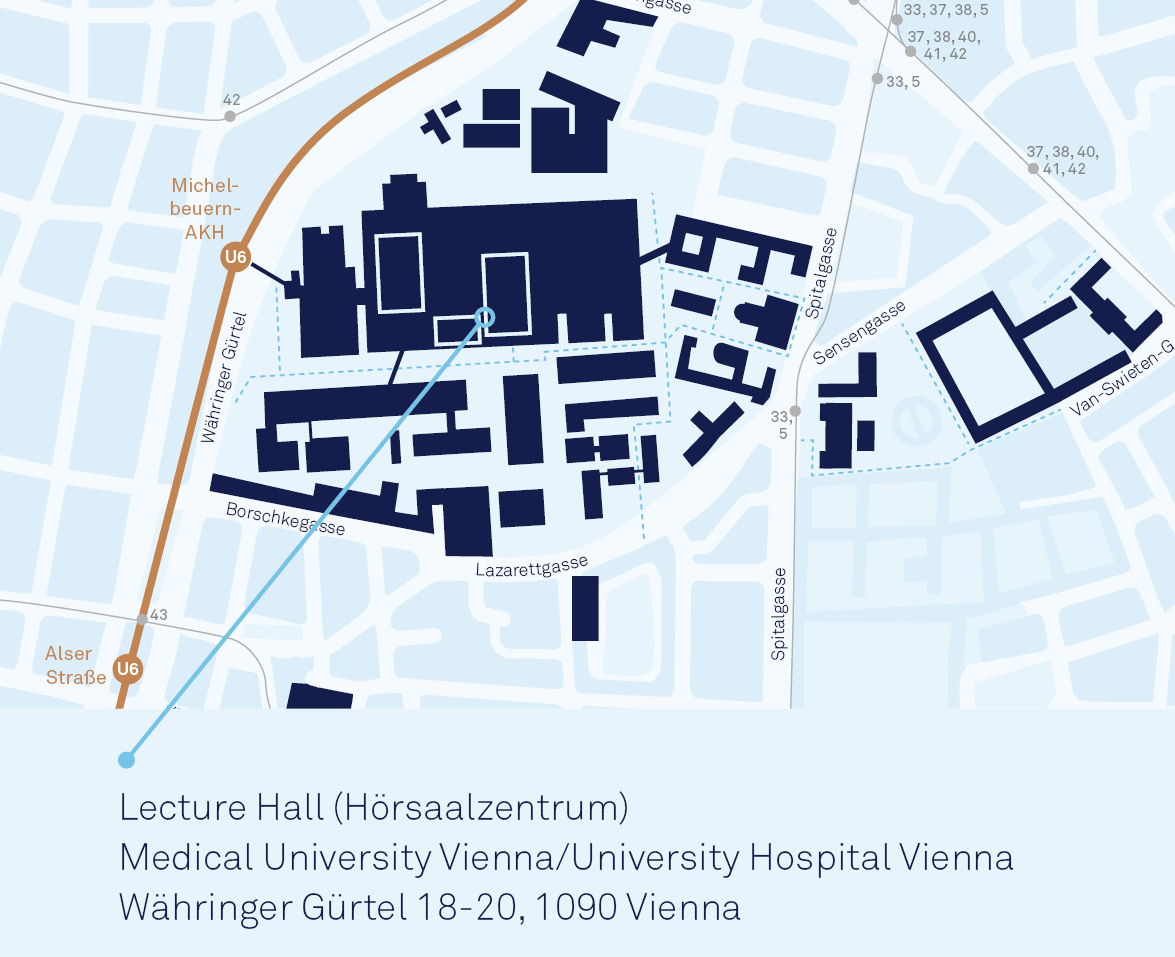
Währinger Gürtel 18-20, 1090 Vienna, Austria
How to get there ...